企业宣传网站建设、电子商务网站建设、OA办公系统。联系电话:028-66165255
文章详情
mssql 如何优化访问速度?(8)
第七步:应用反范式化,使用历史表和预计算列
反范式化
如果你正在为一个OLTA(在线事务分析)系统设计数据库,主要指为只读查询优化过的数据仓库,你可以(和应该)在你的数据库中应用反范式化和索引,也就是说,某些数据可以跨多个表存储,但报告和数据分析查询在这种数据库上可能会更快。
但如果你正在为一个OLTP(联机事务处理)系统设计数据库,这样的数据库主要执行数据更新操作(包括插入/更新/删除),我建议你至少实施第一、二、三范式,这样数据冗余可以降到最低,数据存储也可以达到最小化,可管理性也会好一点。
无论我们在OLTP系统上是否应用范式,在数据库上总有大量的读操作(即select查询),当应用了所有优化技术后,如果发现数据检索操作仍然效率低下,此时,你可能需要考虑应用反范式设计了,但问题是如何应用反范式化,以及为什么应用反范式化会提升性能?让我们来看一个简单的例子,答案就在例子中。
假设我们有两个表OrderDetails(ID,ProductID,OrderQty) 和 Products(ID,ProductName)分别存储订单详细信息和产品信息,现在要查询某个客户订购的产品名称和它们的数量,查询SQL语句如下:
FROM OrderDetails INNER JOIN Products
ON OrderDetails.ProductID = Products.ProductID
WHERE SalesOrderID = 47057
如果这两个都是大表,当你应用了所有优化技巧后,查询速度仍然很慢,这时可以考虑以下反范式化设计:
1)在OrderDetails表上添加一列ProductName,并填充好数据;
2)重写上面的SQL语句
FROM OrderDetails
WHERE SalesOrderID = 47057
注意在OrderDetails表上应用了反范式化后,不再需要连接Products表,因此在执行SQL时,SQL引擎不会执行两个表的连接操作,查询速度当然会快一些。
为了提高select操作性能,我们不得不做出一些牺牲,需要在两个地方(OrderDetails 和 Products表)存储相同的数据(ProductName),当我们插入或更新Products 表中的ProductName字段时,不得不同步更新OrderDetails表中的ProductName字段,此外,应用这种反范式化设计时会增加存储资源消耗。
因此在实施反范式化设计时,我们必须在数据冗余和查询操作性能之间进行权衡,同时在应用反范式化后,我们不得不重构某些插入和更新操作代码。有一个重要的原则需要遵守,那就是只有当你应用了所有其它优化技术都还不能将性能提升到理想情况时才使用反范式化。同时还需注意不能使用太多的反范式化设计,那样会使原本清晰的表结构设计变得越来模糊。
历史表
如果你的应用程序中有定期运行的数据检索操作(如报表),如果涉及到大表的检索,可以考虑定期将事务型规范化表中的数据复制到反范式化的单一的历史表中,如利用数据库的Job来完成这个任务,并对这个历史表建立合适的索引,那么周期性执行的数据检索操作可以迁移到这个历史表上,对单个历史表的查询性能肯定比连接多个事务表的查询速度要快得多。
例如,假设有一个连锁商店的月度报表需要3个小时才能执行完毕,你被派去优化这个报表,目的只有一个:最小化执行时间。那么你除了应用其它优化技巧外,还可以采取以下手段:
1)使用反范式化结构创建一个历史表,并对销售数据建立合适的索引;
2)在SQL Server上创建一个定期执行的操作,每隔24小时运行一次,在半夜往历史表中填充数据;
3)修改报表代码,从历史表获取数据。
创建定期执行的操作
按照下面的步骤在SQL Server中创建一个定期执行的操作,定期从事务表中提取数据填充到历史表中。
1)首先确保SQL Server代理服务处于运行状态;
2)在SQL Server配置管理器中展开SQL Server代理节点,在“作业”节点上创建一个新作业,在“常规”标签页中,输入作业名称和描述文字;
3)在“步骤”标签页中,点击“新建”按钮创建一个新的作业步骤,输入名字和TSQL代码,最后保存;
4)切换到“调度”标签页,点击“新建”按钮创建一个新调度计划;
5)最后保存调度计划。
在数据插入和更新中提前执行耗时的计算,简化查询
大多数情况下,你会看到你的应用程序是一个接一个地执行数据插入或更新操作,一次只涉及到一条记录,但数据检索操作可能同时涉及到多条记录。
如果你的查询中包括一个复杂的计算操作,毫无疑问这将导致整体的查询性能下降,你可以考虑下面的解决办法:
1)在表中创建额外的一列,包含计算的值;
2)为插入和更新事件创建一个触发器,使用相同的计算逻辑计算值,计算完成后更新到新建的列;
3)使用新创建的列替换查询中的计算逻辑。
实施完上述步骤后,插入和更新操作可能会更慢一点,因为每次插入和更新时触发器都会执行一下,但数据检索操作会比之前快得多,因为执行查询时,数据库引擎不会执行计算操作了。
小结
至此,我们已经应用了索引,重构TSQL,应用高级索引,反范式化,以及历史表加速数据检索速度,但性能优化是一个永无终点的过程,最下一篇文章中我们将会介绍如何诊断数据库性能问题。
诊断数据库性能问题就象医生诊断病人病情一样,既要结合自己积累的经验,又要依靠科学的诊断报告,才能准确地判断问题的根源在哪里。前面三篇文章我们介绍了许多优化数据库性能的方法,固然掌握优化技巧很重要,但诊断数据库性能问题是优化的前提,本文就介绍一下如何诊断数据库性能问题。
第八步:使用SQL事件探查器和性能监控工具有效地诊断性能问题
在SQL Server应用领域SQL事件探查器可能是最著名的性能故障排除工具,大多数情况下,当得到一个性能问题报告后,一般首先启动它进行诊断。
你可能已经知道,SQL事件探查器是一个跟踪和监控SQL Server实例的图形化工具,主要用于分析和衡量在数据库服务器上执行的TSQL性能,你可以捕捉服务器实例上的每个事件,将其保存到文件或表中供以后分析。例如,如果生产数据库速度很慢,你可以使用SQL事件探查器查看哪些存储过程执行时耗时过多。
SQL事件探查器的基本用法
你可能已经知道如何使用它,那么你可以跳过这一小节,但我还是要重复一下,也许有许多新手阅读本文。
1)启动SQL事件探查器,连接到目标数据库实例,创建一个新跟踪,指定一个跟踪模板(跟踪模板预置了一些事件和用于跟踪的列),如图1所示;

图 1 选择跟踪模板
2)作为可选的一步,你还可以选择特定事件和列
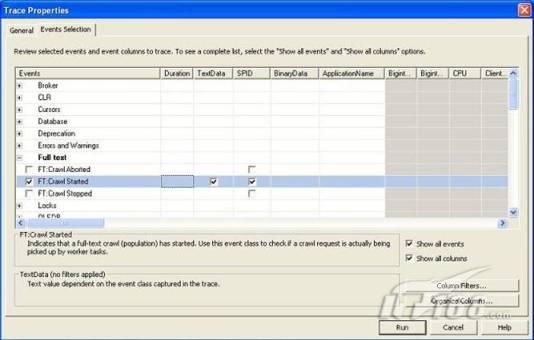
图 2 选择跟踪过程要捕捉的事件
3)另外你还可以点击“组织列”按钮,在弹出的窗口中指定列的显示顺序,点击“列过滤器”按钮,在弹出的窗口中设置过滤器,例如,通过设置数据库的名称(在like文本框中),只跟踪特定的数据库,如果不设置过滤器,SQL事件探查器会捕捉所有的事件,跟踪的信息会非常多,要找出有用的关键信息就如大海捞针。

图 3 过滤器设置
4)运行事件探查器,等待捕捉事件
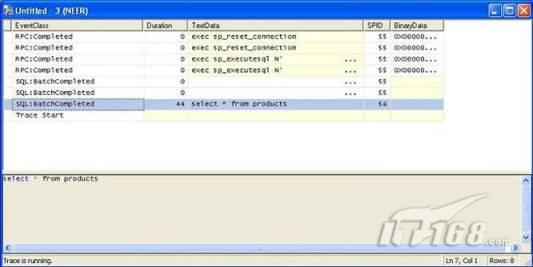
图 4 运行事件探查器
5)跟踪了足够的信息后,停掉事件探查器,将跟踪信息保存到一个文件中,或者保存到一个数据表中,如果保存到表中,需要指定表名,SQL Server会自动创建表中的字段。

图 5 将探查器跟踪数据保存到表中
6)执行下面的SQL查询语句找出执行代价较高的TSQL
Duration DESC

图 6 查找成本最高的TSQL/存储过程
上一篇:最佳数据仓库体系--Hadoop
下一篇:已经是最后一篇