企业宣传网站建设、电子商务网站建设、OA办公系统。联系电话:028-66165255
文章详情
mssql 如何优化访问速度?(5)
15、在存储过程中使用下列最佳实践
(1)不要使用SP_xxx作为命名约定,它会导致额外的搜索,增加I/O(因为系统存储过程的名字就是以SP_开头的),同时这么做还会增加与系统存储过程名称冲突的几率;
(2)将Nocount设置为On避免额外的网络开销;
(3)当索引结构发生变化时,在EXECUTE语句中(第一次)使用WITH RECOMPILE子句,以便存储过程可以利用最新创建的索引;
(4)使用默认的参数值更易于调试。
16、在触发器中使用下列最佳实践
(1)最好不要使用触发器,触发一个触发器,执行一个触发器事件本身就是一个耗费资源的过程;
(2)如果能够使用约束实现的,尽量不要使用触发器;
(3)不要为不同的触发事件(Insert,Update和Delete)使用相同的触发器;
(4)不要在触发器中使用事务型代码。
17、在视图中使用下列最佳实践
(1)为重新使用复杂的TSQL块使用视图,并开启索引视图;
(2)如果你不想让用户意外修改表结构,使用视图时加上SCHEMABINDING选项;
(3)如果只从单个表中检索数据,就不需要使用视图了,如果在这种情况下使用视图反倒会增加系统开销,一般视图会涉及多个表时才有用。
18、在事务中使用下列最佳实践
(1)SQL Server 2005之前,在BEGIN TRANSACTION之后,每个子查询修改语句时,必须检查@@ERROR的值,如果值不等于0,那么最后的语句可能会导致一个错误,如果发生任何错误,事务必须回滚。从SQL Server 2005开始,Try..Catch..代码块可以处理TSQL中的事务,因此在事务型代码中最好加上Try…Catch…;
(2)避免使用嵌套事务,使用@@TRANCOUNT变量检查事务是否需要启动(为了避免嵌套事务);
(3)尽可能晚启动事务,提交和回滚事务要尽可能快,以减少资源锁定时间。
要完全列举最佳实践不是本文的初衷,当你了解了这些技巧后就应该拿来使用,否则了解了也没有价值。此外,你还需要评审和监视数据访问代码是否遵循下列标准和最佳实践。
如何分析和识别你的TSQL中改进的范围?
理想情况下,大家都想预防疾病,而不是等病发了去治疗。但实际上这个愿望根本无法实现,即使你的团队成员全都是专家级人物,我也知道你有进行评审,但代码仍然一团糟,因此需要知道如何治疗疾病一样重要。
首先需要知道如何诊断性能问题,诊断就得分析TSQL,找出瓶颈,然后重构,要找出瓶颈就得先学会分析执行计划。
理解查询执行计划
当你将SQL语句发给SQL Server引擎后,SQL Server首先要确定最合理的执行方法,查询优化器会使用很多信息,如数据分布统计,索引结构,元数据和其它信息,分析多种可能的执行计划,最后选择一个最佳的执行计划。
可以使用SQL Server Management Studio预览和分析执行计划,写好SQL语句后,点击SQL Server Management Studio上的评估执行计划按钮查看执行计划,如图1所示。
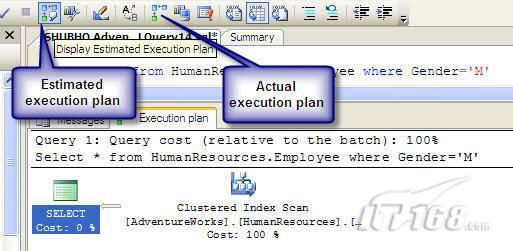
图 1 在Management Studio中评估执行计划
在执行计划图中的每个图标代表计划中的一个行为(操作),应从右到左阅读执行计划,每个行为都一个相对于总体执行成本(100%)的成本百分比。
在上面的执行计划图中,右边的那个图标表示在HumanResources表上的一个“聚集索引扫描”操作(阅读表中所有主键索引值),需要100%的总体查询执行成本,图中左边那个图标表示一个select操作,它只需要0%的总体查询执行成本。
下面是一些比较重要的图标及其对应的操作:

图 2 常见的重要图标及对应的操作
注意执行计划中的查询成本,如果说成本等于100%,那很可能在批处理中就只有这个查询,如果在一个查询窗口中有多个查询同时执行,那它们肯定有各自的成本百分比(小于100%)。
如果想知道执行计划中每个操作详细情况,将鼠标指针移到对应的图标上即可,你会看到类似于下面的这样一个窗口。
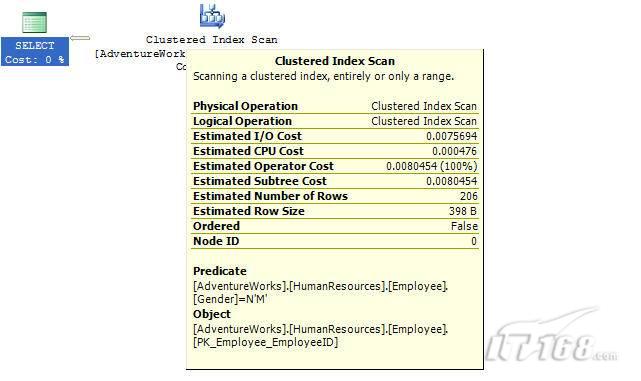
图 3 查看执行计划中行为(操作)的详细信息
这个窗口提供了详细的评估信息,上图显示了聚集索引扫描的详细信息,它要查找AdventureWorks数据库HumanResources方案下Employee表中 Gender = ‘M’的行,它也显示了评估的I/O,CPU成本。
查看执行计划时,我们应该获得什么信息
当你的查询很慢时,你就应该看看预估的执行计划(当然也可以查看真实的执行计划),找出耗时最多的操作,注意观察以下成本通常较高的操作:
1、表扫描(Table Scan)
当表没有聚集索引时就会发生,这时只要创建聚集索引或重整索引一般都可以解决问题。
2、聚集索引扫描(Clustered Index Scan)
有时可以认为等同于表扫描,当某列上的非聚集索引无效时会发生,这时只要创建一个非聚集索引就ok了。
3、哈希连接(Hash Join)
当连接两个表的列没有被索引时会发生,只需在这些列上创建索引即可。
4、嵌套循环(Nested Loops)
当非聚集索引不包括select查询清单的列时会发生,只需要创建覆盖索引问题即可解决。
5、RID查找(RID Lookup)
当你有一个非聚集索引,但相同的表上却没有聚集索引时会发生,此时数据库引擎会使用行ID查找真实的行,这时一个代价高的操作,这时只要在该表上创建聚集索引即可。
TSQL重构真实的故事
只有解决了实际的问题后,知识才转变为价值。当我们检查应用程序性能时,发现一个存储过程比我们预期的执行得慢得多,在生产数据库中检索一个月的销售数据居然要50秒,下面就是这个存储过程的执行语句:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009,’Cap’
Tom受命来优化这个存储过程,下面是这个存储过程的代码:
@startYear DateTime,
@endYear DateTime,
@keyword nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
SELECT
Name,
ProductNumber,
ProductRates.CurrentProductRate Rate,
ProductRates.CurrentDiscount Discount,
OrderQty Qty,
dbo.ufnGetLineTotal(SalesOrderDetailID) Total,
OrderDate,
DetailedDescription
FROM
Products INNER JOIN OrderDetails
ON Products.ProductID = OrderDetails.ProductID
INNER JOIN Orders
ON Orders.SalesOrderID = OrderDetails.SalesOrderID
INNER JOIN ProductRates
ON
Products.ProductID = ProductRates.ProductID
WHERE
OrderDate between @startYear and @endYear
AND
(
ProductName LIKE '' + @keyword + ' %' OR
ProductName LIKE '% ' + @keyword + ' ' + '%' OR
ProductName LIKE '% ' + @keyword + '%' OR
Keyword LIKE '' + @keyword + ' %' OR
Keyword LIKE '% ' + @keyword + ' ' + '%' OR
Keyword LIKE '% ' + @keyword + '%'
)
ORDER BY
ProductName
END
GO
上一篇:最佳数据仓库体系--Hadoop
下一篇:已经是最后一篇